Τι είναι η απόξεση του Web; Πώς να συλλέξετε δεδομένα από ιστότοπους
Διαφήμιση
Οι διαχωριστές ιστού συλλέγουν αυτόματα πληροφορίες και δεδομένα που συνήθως είναι προσβάσιμα μόνο με την επίσκεψη σε έναν ιστότοπο σε ένα πρόγραμμα περιήγησης. Κάνοντας αυτό αυτόνομα, τα σενάρια απόξεσης ιστού ανοίγουν έναν κόσμο δυνατοτήτων στην εξόρυξη δεδομένων, την ανάλυση δεδομένων, τη στατιστική ανάλυση και πολλά άλλα.
Γιατί η αξιοποίηση του Web Scraping είναι χρήσιμη
Ζούμε σε μια εποχή όπου οι πληροφορίες είναι πιο εύκολα διαθέσιμες από κάθε άλλη φορά. Η υποδομή που χρησιμοποιείται για να παραδώσει αυτές τις λέξεις που διαβάζετε είναι ένας αγωγός για περισσότερες γνώσεις, γνώμες και ειδήσεις από ό, τι ήταν ποτέ προσβάσιμο στους ανθρώπους στην ιστορία των ανθρώπων.
Έτσι, στην πραγματικότητα, ο εγκέφαλος του πιο έξυπνου ατόμου, ενισχυμένος σε απόδοση 100% (κάποιος πρέπει να κάνει μια ταινία γι 'αυτό), δεν θα μπορούσε να κρατήσει το 1/1000 των δεδομένων που είναι αποθηκευμένα στο διαδίκτυο μόνο στις Ηνωμένες Πολιτείες .
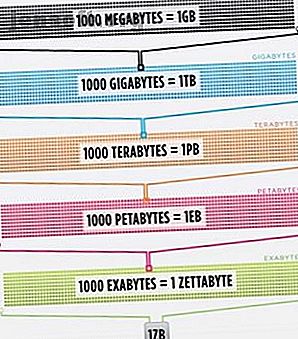
Η Cisco εκτιμά το 2016 ότι η επισκεψιμότητα στο Διαδίκτυο υπερβαίνει ένα zettabyte, το οποίο είναι 1.000.000.000.000.000.000.000 bytes ή ένα bytestillion bytes (προχωρήστε, giggle στο sextillion). Ένα zettabyte είναι περίπου τέσσερα χιλιάδες χρόνια streaming Netflix. Αυτό θα ισοδυναμούσε με το εάν, ανυπόμονος αναγνώστης, θα έπαιρνα το Γραφείο από την αρχή μέχρι το τέλος χωρίς να σταματήσει 500.000 φορές.

Όλα αυτά τα στοιχεία και οι πληροφορίες είναι πολύ εκφοβιστικές. Δεν είναι όλα σωστά. Το μεγαλύτερο μέρος του δεν είναι σχετικό με την καθημερινή ζωή, αλλά όλο και περισσότερες συσκευές παρέχουν αυτές τις πληροφορίες από διακομιστές σε όλο τον κόσμο, στα μάτια μας και στο μυαλό μας.
Καθώς τα μάτια και τα μυαλά μας δεν μπορούν να χειριστούν όλες αυτές τις πληροφορίες, η απόξεση ιστού έχει αναδειχθεί ως μια χρήσιμη μέθοδος για τη συλλογή δεδομένων προγραμματικά από το διαδίκτυο. Η απόξεση ιστού είναι ο αφηρημένος όρος για τον ορισμό της πράξης εξαγωγής δεδομένων από ιστότοπους προκειμένου να το αποθηκεύσετε τοπικά.
Σκεφτείτε ένα είδος δεδομένων και πιθανώς να το συλλέξετε με απόξεση του ιστού. Οι λίστες ακινήτων, τα αθλητικά δεδομένα, οι διευθύνσεις ηλεκτρονικού ταχυδρομείου των επιχειρήσεων στην περιοχή σας και ακόμη και οι στίχοι από τον αγαπημένο σας καλλιτέχνη μπορούν να αναζητηθούν και να αποθηκευτούν γράφοντας ένα μικρό σενάριο.
Πώς ένας φυλλομετρητής αποκτά δεδομένα Web;
Για να κατανοήσουμε τους διαγραμμιστές ιστού, θα πρέπει να κατανοήσουμε πρώτα πώς λειτουργεί ο ιστός. Για να φτάσετε σε αυτόν τον ιστότοπο, πληκτρολογήσατε είτε "makeuseof.com" στο πρόγραμμα περιήγησης ιστού σας είτε κάνατε κλικ σε μια σύνδεση από άλλη ιστοσελίδα (πείτε μας πού, σοβαρά θέλουμε να μάθουμε). Είτε έτσι είτε αλλιώς, τα επόμενα δύο βήματα είναι τα ίδια.
Κατ 'αρχάς, το πρόγραμμα περιήγησής σας θα πάρει τη διεύθυνση URL που εισαγάγατε ή κάντε κλικ (Pro-tip: τοποθετήστε το δείκτη του ποντικιού πάνω από το σύνδεσμο για να δείτε τη διεύθυνση URL στο κάτω μέρος του προγράμματος περιήγησης πριν κάνετε κλικ για να αποφύγετε punk'd) και να δημιουργήσετε ένα "αίτημα" σε ένα διακομιστή. Στη συνέχεια ο διακομιστής θα επεξεργαστεί το αίτημα και θα στείλει μια απάντηση πίσω.
Η απάντηση του διακομιστή περιέχει τα HTML, JavaScript, CSS, JSON και άλλα δεδομένα που απαιτούνται για να επιτρέψουν στο πρόγραμμα περιήγησης ιστού να σχηματίσει μια ιστοσελίδα για την ευχαρίστησή σας.
Έλεγχος στοιχείων ιστού
Τα σύγχρονα προγράμματα περιήγησης μας επιτρέπουν ορισμένες λεπτομέρειες σχετικά με αυτή τη διαδικασία. Στο Google Chrome στα Windows μπορείτε να πατήσετε Ctrl + Shift + I ή δεξί κλικ και να επιλέξετε Επιθεώρηση . Το παράθυρο θα παρουσιάσει στη συνέχεια μια οθόνη που μοιάζει με την ακόλουθη.

Μια λίστα καρτελών με επιλογές εμφανίζει το επάνω μέρος του παραθύρου. Το ενδιαφέρον τώρα είναι η καρτέλα Δίκτυο . Αυτό θα δώσει λεπτομέρειες για την κίνηση HTTP όπως φαίνεται παρακάτω.

Στην κάτω δεξιά γωνία βλέπουμε πληροφορίες σχετικά με το αίτημα HTTP. Η διεύθυνση URL είναι αυτό που περιμένουμε και η "μέθοδος" είναι ένα αίτημα HTTP "GET". Ο κωδικός κατάστασης από την απάντηση παρατίθεται ως 200, πράγμα που σημαίνει ότι ο διακομιστής είδε το αίτημα ως έγκυρο.
Κάτω από τον κωδικό κατάστασης είναι η απομακρυσμένη διεύθυνση, η οποία είναι η δημόσια διεύθυνση IP που βρίσκεται στο διακομιστή makeuseof.com. Ο πελάτης παίρνει αυτή τη διεύθυνση μέσω του πρωτοκόλλου DNS Γιατί η αλλαγή των ρυθμίσεων DNS αυξάνει την ταχύτητα του Internet σας Γιατί η αλλαγή των ρυθμίσεων DNS αυξάνει την ταχύτητα του Internet Αλλαγή των ρυθμίσεων DNS σας είναι ένα από αυτά τα δευτερεύοντα tweaks που μπορούν να έχουν μεγάλες αποδόσεις στις καθημερινές ταχύτητες του Διαδικτύου. Διαβάστε περισσότερα .
Η επόμενη ενότητα αναφέρει λεπτομέρειες σχετικά με την απάντηση. Η κεφαλίδα απόκρισης περιέχει όχι μόνο τον κωδικό κατάστασης, αλλά και τον τύπο δεδομένων ή περιεχομένου που περιέχει η απάντηση. Σε αυτή την περίπτωση, εξετάζουμε το "text / html" με μια τυπική κωδικοποίηση. Αυτό μας λέει ότι η απάντηση είναι κυριολεκτικά ο κώδικας HTML για την απόδοση του ιστότοπου.

Άλλοι τύποι απαντήσεων
Επιπλέον, οι διακομιστές μπορούν να επιστρέψουν αντικείμενα δεδομένων ως απάντηση σε ένα αίτημα GET, αντί για HTML μόνο για την απόδοση της ιστοσελίδας. (API) Τι είναι τα API και πώς είναι τα ανοικτά API Αλλαγή του Διαδικτύου Ποια είναι τα API και πώς ανοίγονται τα API Αλλαγή του Διαδικτύου Έχετε ποτέ αναρωτηθεί πώς τα προγράμματα στον υπολογιστή σας και στους ιστοτόπους που επισκέπτεστε "μιλάτε" ο ένας στον άλλον? Διαβάστε πιο τυπικά χρησιμοποιεί αυτό το είδος ανταλλαγής.
Αν μεταβείτε στην καρτέλα "Δίκτυο" όπως φαίνεται παραπάνω, μπορείτε να δείτε αν υπάρχει αυτός ο τύπος ανταλλαγής. Όταν εξετάζετε το Open Leaderboard του CrossFit, εμφανίζεται το αίτημα για συμπλήρωση του πίνακα με δεδομένα.

Κάνοντας κλικ στην απάντηση, εμφανίζονται τα δεδομένα JSON αντί για τον κώδικα HTML για απόδοση του ιστότοπου. Τα δεδομένα σε JSON είναι μια σειρά ετικετών και τιμών, σε μια πολυεπίπεδη λίστα.

Η χειρωνακτική ανάλυση του κώδικα HTML ή η μετάβαση σε χιλιάδες ζεύγη κλειδιών / τιμών του JSON είναι πολύ παρόμοια με την ανάγνωση του Matrix. Με την πρώτη ματιά, μοιάζει αδύναμη. Μπορεί να υπάρχουν πάρα πολλές πληροφορίες για χειροκίνητη αποκωδικοποίηση.
Web Scrapers στη διάσωση!
Τώρα προτού να ζητήσετε το μπλε χάπι για να βγείτε από εδώ, θα πρέπει να ξέρετε ότι δεν χρειάζεται να κάνετε χειροκίνητη αποκωδικοποίηση κώδικα HTML! Η άγνοια δεν είναι ευτυχία, και αυτή η μπριζόλα είναι υπέροχη.
Ένας αποξεστήρας ιστού μπορεί να εκτελέσει αυτές τις δύσκολες εργασίες για σας Το API Scrapestack κάνει εύκολο να ξύσει ιστοσελίδες για δεδομένα Το Scrapestack API καθιστά εύκολο να ξύσει ιστοσελίδες για τα δεδομένα Ψάχνετε για ένα ισχυρό και προσιτό web ξύστρα; Το API scrapestack είναι ελεύθερο να ξεκινήσει και προσφέρει πολλά χρήσιμα εργαλεία. Διαβάστε περισσότερα . Τα πλαίσια απομάκρυνσης είναι διαθέσιμα σε Python, JavaScript, κόμβο και άλλες γλώσσες. Ένας από τους ευκολότερους τρόπους για να ξεκινήσετε την απόξεση είναι η χρήση της Python και της Beautiful Soup.
Κρατώντας μια ιστοσελίδα με την Python
Για να ξεκινήσετε μόνο μερικές γραμμές κώδικα, αρκεί να έχετε εγκαταστήσει Python και BeautifulSoup. Εδώ είναι ένα μικρό σενάριο για να πάρετε την πηγή ενός ιστοτόπου και αφήστε το BeautifulSoup να το αξιολογήσει.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Πολύ απλά, κάνουμε ένα αίτημα GET σε μια διεύθυνση URL και στη συνέχεια βάζουμε την απάντηση σε ένα αντικείμενο. Η εκτύπωση του αντικειμένου εμφανίζει τον πηγαίο κώδικα HTML της διεύθυνσης URL. Η διαδικασία είναι σαν να πήγαμε μη αυτόματα στον ιστότοπο και να κάνετε κλικ στην επιλογή Προβολή προέλευσης .
Συγκεκριμένα, αυτός είναι ένας ιστότοπος που δημοσιεύει workouts σε στυλ CrossFit καθημερινά, αλλά μόνο ένα ανά ημέρα. Μπορούμε να κατασκευάσουμε τον αποξεστήρα μας για να πάρουμε την προπόνηση κάθε μέρα, και στη συνέχεια να την προσθέσουμε σε μια συγκεντρωτική λίστα των προπονήσεων. Ουσιαστικά, μπορούμε να δημιουργήσουμε μια ιστορική βάση δεδομένων που να βασίζεται σε κείμενα των προπονήσεων που μπορούμε εύκολα να αναζητήσουμε.
Η μαγεία του BeaufiulSoup είναι η δυνατότητα αναζήτησης σε όλο τον κώδικα HTML χρησιμοποιώντας την ενσωματωμένη λειτουργία findAll (). Στη συγκεκριμένη περίπτωση, ο ιστότοπος χρησιμοποιεί πολλές ετικέτες "sqs-block-content". Ως εκ τούτου, το σενάριο πρέπει να βρόχο σε όλες αυτές τις ετικέτες και να βρείτε αυτό που μας ενδιαφέρει.
Επιπλέον, υπάρχουν ορισμένοι
ετικέτες στην ενότητα. Το σενάριο μπορεί να προσθέσει όλο το κείμενο από κάθε μία από αυτές τις ετικέτες σε μια τοπική μεταβλητή. Για να το κάνετε αυτό, προσθέστε ένα απλό βρόχο στο script:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! Έχει δημιουργηθεί ένας αποξεστήρας ιστού.
Μεγέθυνση της απόξεσης
Δύο μονοπάτια υπάρχουν για να προχωρήσουμε.
Ένας τρόπος για να εξερευνήσετε την απόξεση ιστού είναι να χρησιμοποιήσετε εργαλεία που έχουν ήδη κατασκευαστεί. Το Web Scraper (υπέροχο όνομα!) Έχει 200.000 χρήστες και είναι απλό στη χρήση. Επίσης, το Parse Hub επιτρέπει στους χρήστες να εξάγουν δεδομένα με απόξεση σε Excel και στο Google Sheets.
Επιπλέον, το Web Scraper παρέχει μια προσθήκη Chrome που βοηθά στην απεικόνιση του τρόπου κατασκευής ενός ιστότοπου. Το καλύτερο από όλα, κρίνοντας από το όνομα, είναι το OctoParse, ένα ισχυρό ξύστρα με μια διαισθητική διασύνδεση.
Τέλος, τώρα που γνωρίζετε το ιστορικό της αποξένωσης του ιστού, αυξάνοντας το δικό σας μικρό εργαλείο αποξένωσης ιστού για να μπορέσετε να ανιχνεύσετε και να εκτελέσετε το πώς να δημιουργήσετε ένα βασικό crawler στο Web για να τραβήξετε πληροφορίες από έναν ιστότοπο Πώς να χτίσετε ένα βασικό ανιχνευτή ιστού για να τραβήξετε πληροφορίες από ένα Ιστοσελίδα Έχετε ποτέ θελήσει να συλλέξετε πληροφορίες από έναν ιστότοπο; Μπορείτε να γράψετε ένα πρόγραμμα ανίχνευσης για να περιηγηθείτε στον ιστότοπο και να εξαγάγετε ακριβώς αυτό που χρειάζεστε. Διαβάστε περισσότερα από μόνος του είναι μια διασκεδαστική προσπάθεια.
Εξερευνήστε περισσότερα σχετικά με: Python, Web Scraping.

